您现在的位置是:网站首页> 编程资料编程资料
XXencode 编码,XX编码介绍、XXencode编码转换原理与算法_其它综合_
![]() 2023-05-27
781人已围观
2023-05-27
781人已围观
简介 XXencode 编码,XX编码介绍、XXencode编码转换原理与算法_其它综合_
Xxencode编码,也是一个二进制字符转换为普通打印字符方法。跟UUencode编码原理方法很相似,唯独不同的是可打印字符不同。通个UUencode编码,我们知道它有个缺点就是,64个可打印字符中,有很多的特殊字符。而XXencode编码方法,对64个原字符有做规范。这里它有跟Base64类型了。都有指定可打印字符范围、及编号。Xxencode编码在上世纪后期,IBM大型机中得到很广泛的应用。现在逐渐被Base64编码转换方法所取代了。
Xxencode编码原理
XXencode将输入文本以每三个字节为单位进行编码。如果最后剩下的资料少于三个字节,不够的部份用零补齐。这三个字节共有24个Bit,以6bit为单位分为4个组,每个组以十进制来表示所出现的数值只会落在0到63之间。以所对应值的位置字符代替。它所选择的可打印字符是:+-0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz,一共64个字符。跟base64打印字符相比,就是uuencode多一个“-” 字符,少一个”/” 字符。 但是,它里面字符顺序与Base64完全不一样。与UUencode比较,这里面所选择字符,都是常见字符,没有特殊字符。这也决定它当年流行使用原因!
每60个编码输出(相当于45个输入字节)将输出为独立的一行,每行的开头会加上长度字符,除了最后一行之外,长度字符都应该是“h”这个字符(45,刚好是64字符中,第45位'h'字符),最后一行的长度字符为剩下的字节数目 在64字符中位置所代表字符。
问题:uuencode编码转换为xxencode编码怎么样操作?
从2中编码原理来看,几乎一样。就是所用的64个字符不一样。一次,简单对uuencode转换后字符,逐位(处理'`'字符)减去32,然后得到一个值。这个值在xxencode 64字符中所对应位置字符替换即可。
XXencode编码转换过程
| 原始字符 | C | a | t | |||||||||||||||||||||
| 原始ASCII码(十进制) | 67 | 97 | 116 | |||||||||||||||||||||
| ASCII码(二进制) | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 0 |
| 新的十进制数值 | 16 | 54 | 5 | 52 | ||||||||||||||||||||
| 编码后的XXencode字符 | E | q | 3 | O | ||||||||||||||||||||
XXencode编码PHP实现过程
/** *xxencode编码* *@author 程默 *@copyright http://blog.chacuo.net/ *@param string $src 待处理字符串 *@return string encode编码完字符串 */ function c_xx_encode($src) { //64个可打印字符 static $base="+-0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"; ///每次读取3个字节 $lbyte = 3; ////将原始的3个字节转换为4个字节 $slen=strlen($src); $smod = ($slen%$lbyte); $snum = floor($slen/$lbyte); $desc = array(); //将剩下字节以0字节补齐 $src = $smod===0?$src:$src.str_repeat("\0",$lbyte-$smod); $snum = $smod===0?$snum:$snum+1; for($i=0;$i<$snum;$i++) { ////读取3个字节 $_arr = array_map('ord',str_split(substr($src,$i*$lbyte,$lbyte))); ///计算每一个6位值 $_dec = array(); $_dec[]=$_arr[0]>>2; $_dec[]=(($_arr[0]&3)<<4)|($_arr[1]>>4); $_dec[]=(($_arr[1]&0xF)<<2)|($_arr[2]>>6); $_dec[]=$_arr[2]&63; ///求每一位值,在64字符中所对应的字符 foreach ($_dec as &$v) { $v=$base[$v]; } $desc = array_merge($desc,$_dec); } //每60个编码输出(相当于45个输入字节)将输出为独立的一行,每行的开头会加上长度字符,除了最后一行之外,长度字符都应该是'h'这个ASCII字符(45),最后一行的长度字符为剩下的字节数目,在64字符中对应字符。 $abyte = 60; $crlf = "\r\n"; $alen = count($desc); $anum = floor($alen/$abyte); $amod = ($alen%$abyte); $adesc = array(); for ($i=0;$i<$anum;$i++) { $adesc[]='h'.implode('',array_slice($desc,$i*$abyte,$abyte)).$crlf; } ///截取后面剩余数组长度 if($amod!==0) { ///以下计算不满45字节编码情况 $adesc[]=$base[$amod/4*$lbyte+($smod?$smod-$lbyte:$smod)].implode('',array_slice($desc,-$amod)).$crlf; } return implode('',$adesc); }以上代码从uuencode编码做简单修改而来,基本上去掉+32一些地方。知道编码原理,其实我们很容易实现uuencode->xxencode转换的
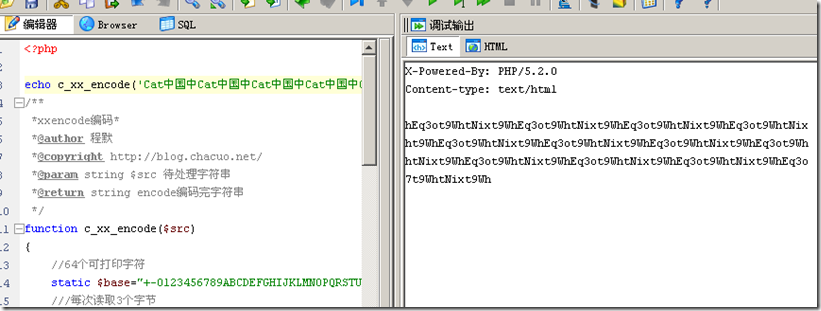

以上转换后结果,与专业转换工具一致的。好了,通过学习这类用可打印字符表示二进制字节的编码方法。我们可以发现很多有趣东西!对应以后我们如果做自己的编码转换,可以给我们很多借鉴!欢迎朋友们给出自己的意见!





